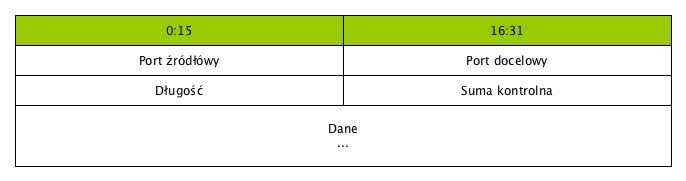
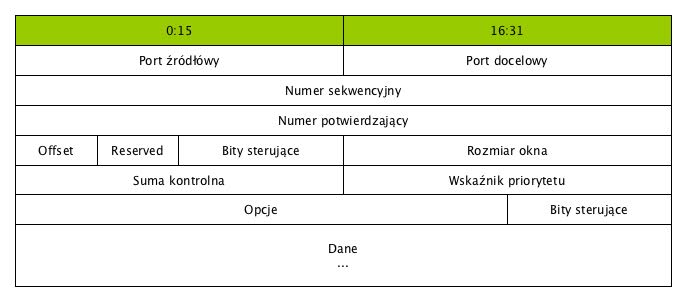
Proces
Proces to swojego rodzaju logiczny kontener, który zawiera m.in.:
- Listę wątków
- Mapę pamięci procesu
- Uchwyty do otwartych plików, połączeń sieciowych, urządzeń itp.
- Dodatkowe informacje potrzebne systemowi do zarządzania danym procesem
- Obsługę sygnałów, procesów potomnych
Wydzielenie takie – w postaci procesu, daje systemowi operacyjnemu możliwość zarządzania uruchomionymi programami. Scheduler systemowy (planista) przydziela czas procesora poszczególnym procesom uruchomionym w systemie. Konieczność przełączania pomiędzy procesami spowodowana jest tym, że danej chwili rdzeń procesora może wykonywać jeden wątek. Z punktu widzenia procesora na komputerze wykonywany jest jeden program, a z punktu widzenia systemu jednocześnie wykonywanych jest wiele programów.
Współczesne procesory mogą wykonywać kilka wątków równocześnie, w zależności od liczby rdzeni. W tym momencie warto zauważyć, że proces po uruchomieniu posiada przynajmniej jeden wątek, z poziomu którego programowo można utworzyć kolejne. Wątek jest odpowidzialny za wykonywanie kodu programu.
Uruchomienie aplikacji powoduje utworzenie w systemie nowego procesu. Wyjątkiem może być np. Skrypt Java Script uruchomiony w przeglądarce, gdzie interpreter jest współdzielony przez wiele skryptów. Każdy proces ma wydzieloną przestrzeń adresową, która jest zapełniania i zwalniana podczas działania programu. Dostęp do tej pamięci przez inne procesy jest ograniczony. Proces zawiera także informacje zarządzane przez system operacyjny np.: identyfikator PID; czas życia uptime; ścieżka do katalogu roboczego; lista otwartych uchwytów; priorytet; lista argumentów.
Tworzenie procesu
Poniżej przedstawiam prosty przykład tworzenia nowego procesu z wykorzystaniem niskopoziomowego API systemów unixowych. Użyta została funkcja fork, która wykonuje kopię obecnego procesu.
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(void)
{
pid_t pid = fork();
if(pid == 0)
{
//Kod procesu dziecka
printf("Child Process\n");
}
else if(pid > 0)
{
//Kod procesu rodzica
printf("Parent Process\n");
}
else
{
//Błąd
perror("Failed to create process\n");
}
return 0;
}Kompilacja i uruchomienie:
gcc -Wall -Wextra fork.c
./a.out
Parent Process
Child ProcessWątek
Wątek w praktyce jest jednostką wykonującą kod programu. Programiści tworzą wiele wątków działających w obrębie jednego procesu w celu uproszczenia struktury/architektury programu, wydzielenia logicznych części programu oraz zwiększenie wydajności przez zrównokeglenie obliczeń.
Różnica pomiędzy wątkiem a procesem polega na tym, że wątki w obrębie tego samego procesu współdzielą między sobą pamięć adresową, uchwyty do urządzeń, plików, połączeń (proces ma przydzielone niezależne zasoby).Dzięki temu wymagają mniej zasobów do działania, krótszy jest ich czas tworzenia/zakończenia, komunikacja/współdzielenie zasobów może odbywać się bez pomocy jądra systemu oraz możliwość szybkiego przełączania kontekstu pomiędzy wątkami tego samego procesu. Możliwość jednoczesnego wykonywania kodu korzystającego z tych samych zasobów wymaga zapewnienia zsynchronizowanego dostępu do danych w celu uniknięcia błędów w obliczeniach, zakleszczenia wątków czy błędów bezpieczeństwa.
Tworzenie wątków
Poniżej przykład utworzenia nowych wątków z wykorzystaniem API zgodnego z POSIX.
#include <stdio.h>
#include <pthread.h>
void *thread_print(void *data);
int main(void)
{
pthread_t th1, th2;
int ret1, ret2;
ret1 = pthread_create(&th1, NULL, thread_print, (void *)"Message 1");
if(ret1 != 0)
{
fprintf(stderr, "Error: creating thread\n");
return 1;
}
ret2 = pthread_create(&th2, NULL, thread_print, (void *)"Message 2");
if(ret2 != 0)
{
fprintf(stderr, "Error: creating thread\n");
return 1;
}
pthread_join(th1, NULL);
pthread_join(th2, NULL);
return 0;
}
void *thread_print(void *data)
{
char *msg = (char *)data;
printf("%s\n", msg);
return NULL;
}Kompilacja i uruchomienie:
gcc -Wall -Wextra thread.c -lpthread
./a.out
Message 1
Message 2