Przy budowie, rozwoju modyfikacji systemów wbudowanych opartych o linux embedded konieczny jest wybór tzw. toolchian’a. Powinien on być dopasowany do architektury procesora.
Czym właściwie jest toolchain?
Toolchain to zestaw narzędzi, w skład którego wchodzi m.in kompilator, linker, biblioteki, debugger. Wykorzystywany jest on do budowy bootloader’a, jądra systemu oraz systemu plików, a później też do budowy aplikacji użytkownika. Mówiąc o budowaniu mam na myśli możliwość skompilowania programów napisanych w językach: asembler, C oraz C++. Ponieważ w tych językach dostarczane są podstawowe elementy systemu. Toolchain zazwyczaj basuje na projekcie GNU GCC. Toolchain może pracować w dwojaki sposób:
- Natywnie: toolchain jest uruchamiany na tym samym typie maszyny co budowana aplikacja. Jest to znane rozwiązanie ze świata komputerów PC.
- Cross: toolchain uruchamiany jest na innej maszynie niż zbudowana aplikacja. Czyli kompilacja aplikacji wykonywana jest na innej architekturze niż docelowa.
Zazwyczaj używane jest podejście cross. W polskiej terminologii funkcjonuje pojecie kompilacji skrośnej na to zagadnienie. Maszyna na której uruchamiany jest toolchain do budowy aplikacji to HOST a maszyna docelowa to TARGET. Podejście takie stosowane jest głównie z takiego powodu, że maszyna host posiada znaczenie większą moc obliczeniową, oraz łatwiejszy dostęp i użytkowanie. Minusem takiego podejścia jest wymóg kompilacji skrośnej oprócz budowanej aplikacji również używanych bibliotek. Co czasem może utrudniać prace. Aby ułatwić pracę programistom powstały do tego celu specjalne narzędzia. Zazwyczaj używa się Buildroot lub Yocto.
Toolchain powinien uwzględniać: architekturę procesora (np. x86, arm, mips), kolejność bajtów (big lub little-endian), wsparcie obliczeń zmienne-przecinkowych, ABI – Application Binary Interface – reguły współpracy między programami, bibliotekami a system operacyjnym i sprzętem.
Nazwa toolchain’a zawiera w sobie informacje o: CPU (np. Arm, mips x86_64), dostawcy toolchiain’a (np. Buildroot, poky), kernel, systemie operacyjnym(np gnu, może być dołączona też informacji o ABI). Informacje te rozdzielone są myślnikiem. Przykładowe nazwy toolchain’ów:
- x86_64-linux-gnu
- arm-linux-gnueabihf
- arm-buildroot-linux-gnueabi
Biblioteka standardowa język C
Język C jest jeżykiem systemów operacyjnych z rodziny Unix. Biblioteka języka C jest wykorzystywana przez każdy program (nawet napisany w innym języku niż C) do komunikacji z jądrem systemu operacyjnego. Używa ona wywołania systemowe do komunikacji z kernelem. Jest interfejsem pomiędzy przestrzenią użytkownika a przestrzenią jądra. Możliwe jest ominięcie biblioteki C poprzez bezpośrednie wywołanie systemowe, ale bywa to utrudnione i zazwyczaj niekonieczne.
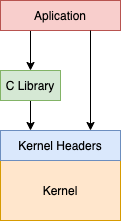
Dostępnych jest kilka implementacji bibilliteki C. Najbardziej popularne to:
- Glibc – biblioteka stworzona w ramach projektu GNU. Najbardziej kompletna implementacja POSIX API.
- eglibc – wersja glibc dla embedded. Dodano opcje konfguracji, wsparcie kilku architektur. Od 2014 nie jest nadal rozwijana. Została złączona z glibc.
- uClibc – implementacja przystosowana pod systemy wbudowane. Jest ona o wiele lżejsza niż glibc. Nie implementuje ona w pełni standardu POSIX, ale można uruchomić z nią większość aplikacji współpracujących z glic. Pierwotnie powstała ona dla systemu uClinux – linux dla procesory bez jednostki zarządzania pamięci.
- musl libc – lekka implementacja biblioteki jezka C dla systemów wbudowanych
- dietlibc – podobnie jak musl libc, odchudzona implementacja biblioteki C. Zawiera najważniejsze i najcześciej używane funkcje.
Wielkość pamięci masowej i RAM determinuje wybór odpowiedniej biblioteki języka C. Użycie dystrybucji uClinux implikuje użycie biblioteki uClibc.